引入一个新开源软件到生产环境,也就开始了维护之旅,由于是新的,所以大概率你对她的设计与实现,并不熟悉,解决起故障来远远没有源作者高效,步骤也多:
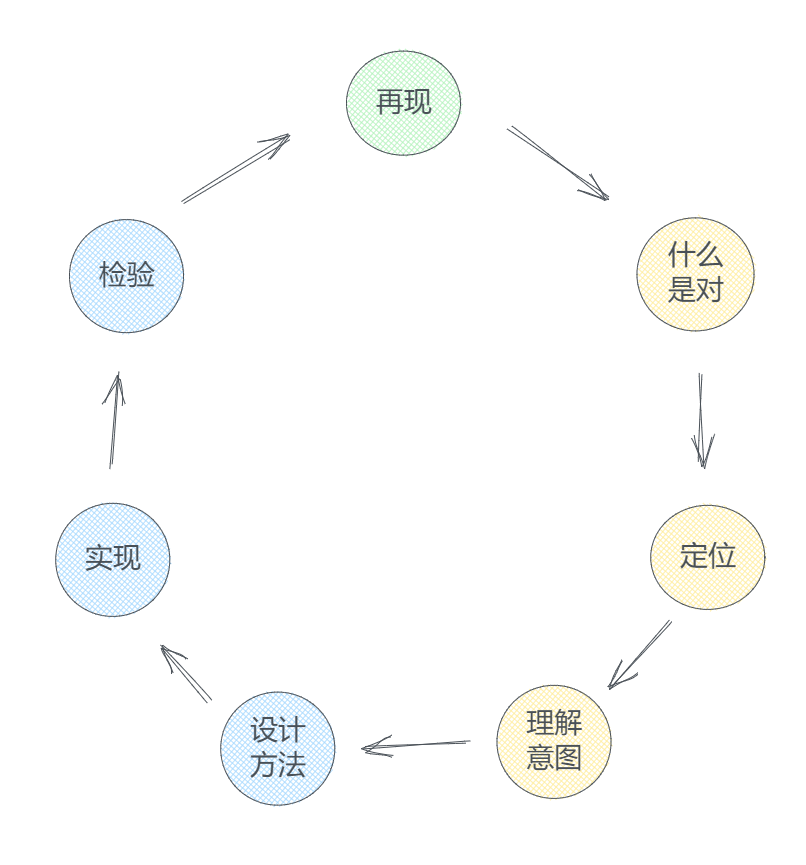
1. 再现
容易再现的故障,跟踪下去就可以找到病灶,而不常发生的,需要在多处怀疑的地方加日志来缩小范围。万一是个稳定性问题,每次爆发的出口都不同,就难定位,这往往需要一些针对性的测试和阅读代码找漏洞、裁剪代码等手段的组合来提高效率。这部分工作可长、可短,存在时间不可控的风险,所以大家总说故障的解决速度取决于再现速度。
2. 什么是对的
如果你对软件的业务功能不熟悉,那么故障对立面的正确是什么,需要去学习。这可以和后面结合起来。
3. 定位
定位到一个代码段后,需要分辨故障原因:
- 内因:自身处理不当。
- 外因:依赖的外界错误,比如传入错误参数。
通常外因牵扯面更广,需要你继续追踪,可能最后发现是一个配置项使用了错误值。
最后当你完成这一步,算是看到了曙光。
4. 理解意图
现有软件做成这样是有意为之还是偶然,如此这般也许是填过很多坑之后的血泪之作,你作为后来者掌握的信息还很片面,除非是明显缺陷,否则你先要去思考前者的设计思路、特点,才能借力、沿着之前的道路继续前行。
5. 设计新办法
以前的设计思路没有覆盖现有的问题,由此可能你发现了一个更大的豁口,你想借机填补,那就干吧,拿出一个新的办法,先说服自己,是否果真是留有以前的好处,同时省时省力地解决新问题。此时最好是能得到开源软件作者们的review。
6. 实现
这里是去不断证明和完善设计,最后变成代码。尽量保持和旧有代码类似的风格,或者不要花费太多时间,因为这大概率不是当前的核心目标。
7. 检验
当你还不熟悉这个软件时,可能做一个完整的测试也会花费时间,此时想要验证一个想法,可以给软件的环境做些限制比如发送特定输入,把这些做成一个个单元测试,以便小范围检验。往往还会因为解决新的问题发现可以弥补一些测试手段,避免同类问题逃逸。
最后,需要你做一个完整的闭环测试,这样才能让你看到这项功能是如何用起来的,更好地去理解功能的价值。
等你完成了这些,就可以去给作者发起PR。